1 July 2008 - 5:48Firefox 3 Smart Location Bar Saves You Time
Now that Firefox 3 [mozilla.com] has been downloaded well over 27 million times [mozilla.com], many people have noticed that the Smart Location Bar can find pages that match not only in the URL but also in the title or tags added to a bookmarked page. One commonly overlooked feature that saves you a lot of time is the ability to quickly narrow down the search results and find exactly what you want. Just type another word.
Typing multiple words and not being restricted to just matching at the beginning of the URL to match the domain provides a lot of power to the user.
I’ve put together some examples of how the Smart Location Bar can save you seconds, even minutes, every day when using websites like YouTube or Gmail or any place you can visit through Firefox. (Don’t miss the pro-tip at the end to easily read your new messages in Gmail! 😀 )
Ever visited a page but don’t remember the site’s URL or even the the domain? When you’re clicking through Google search results, you might find what you’re looking for but forget to make note of the URL. Many times you can just type in what you were searching for and Firefox can find it right away. Firefox will even order the results based on better matches.
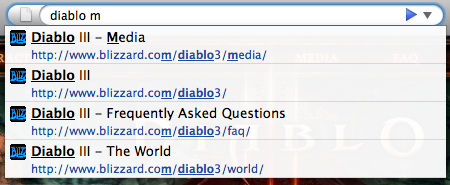
In most other browsers, you would have to start typing out “www.blizzard.com” if you remembered it and then additionally type “/diablo3” to find the Diablo III related pages. Using Firefox 3’s Smart Location Bar, you could easily jump to what you want and perhaps find non-Blizzard pages that you might be interested in because you don’t have to remember to type the domain anymore.
A lot of pages on the Internet have URLs that are completely filled with junk — at least totally unmemorable for the user. Most likely the title of the page will have something much more useful. One prime example is YouTube where the video URLs are just some way for YouTube to know which video you want.
You’re more likely to remember the title of the page, which directly relates to the content of the video that you previously watched, than remembering even half of the random characters used to identify the video.
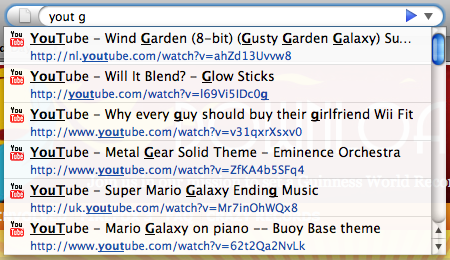
In this case, I was trying to find Wind Garden [youtube.com], an 8-bit remix of a really great song from Super Mario Galaxy. In other browsers, if I wanted to try finding the page from my history and started typing out “yout,” I would never have found it because somebody linked that video to me from nl.youtube.com. I was able to find it with Firefox 3 because “yout” matched in both the title and URL ignoring the “nl.” part.
Another example of the AwesomeBar’s time-saving ability that will be popular with movie watchers is with IMDb – the Internet Movie Database. If you’re like me and can’t remember which movies every actor has been in, you’ll be revisiting this site over and over again. However, instead of always going to to the main IMDb homepage to find a movie using the search box, you can go directly to the page you want with Firefox 3.
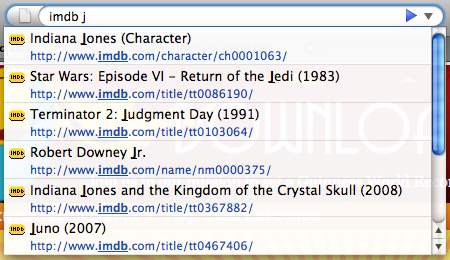
These IMDb results show off yet another strength of the AwesomeBar — being able to match both the URL and title at the same time. Notice that “imdb” only shows up in the url. You can type “imdb” and then a word from the title to quickly narrow down the results to find the exact page you want. This saves you those extra seconds it takes to load the whole IMDb homepage and start a search.
You’ve got phone numbers, account numbers, social security numbers, personal identification numbers, and more numbers to keep track of. There’s no need to additionally keep track of IP addresses for those websites that don’t have easy-to-remember domain names.
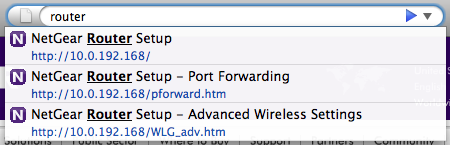
Cellphones let you easily find phone numbers by Contact name, and Firefox 3 lets you find IP addresses by Page name. Just like how you need to enter the contact name and phone number the first time on your phone, you’ll need to type in the the IP address once. But on the up-side, you don’t even need to provide a name for the IP address because Firefox 3 will automatically remember the page’s title for you. 🙂
Gmail has done a great job with their newest version by providing multiple points of access to their web application. Each message can be accessed directly by URL instead of requiring the user to first load the main Gmail page then searching for a message.
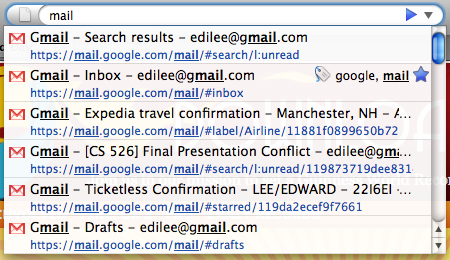
Being able to access these multiple points of entry is facilitated by the AwesomeBar’s match-anywhere functionality. In this case, you would want to match page titles for email titles, but URLs can also be matched for commands like “new doc” for Google Docs [madhava.com].
By combining the AwesomeBar’s adaptive learning [ed.agadak.net] with the ability to start a Gmail search to find unread messages [mail.google.com] plus automatically selecting the first result [addons.mozilla.org] when pressing enter, I’ve been saving a lot of time whenever I check for new messages. All I need to do is type “mail” and press enter.
Digg it! Edit: Updated for post-Firefox 3 launch intro and a couple new examples.
65 Comments | Tags: AwesomeBar, Development, Google, Mozilla, Nintendo